Project Summary
This project has been challenging and frustrating at times but a lot of fun and an amazing learning path after all!
You'll find all the code (minus my private keys) on GitHub: https://github.com/PaulElser/CloudStarter.
It is best to give an overview of what has been done in the last couple of months:
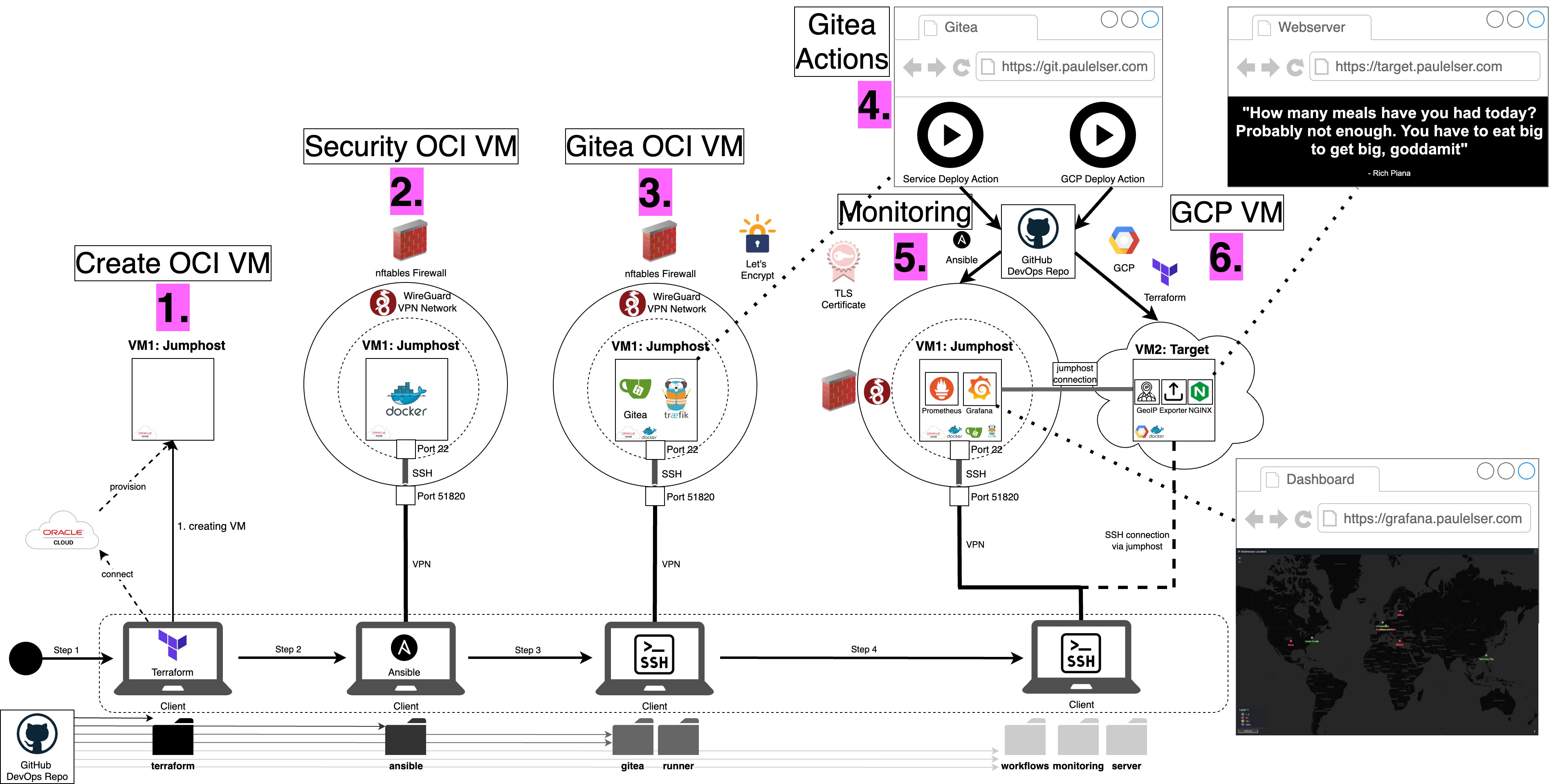
- A new VM on Oracle's OCI has been created by setting up an OCI user account and learning about Terraform scripts and variables.
- A couple of layers of security were necessary for this VM: A WireGuard VPN server has been installed and configured to only accept connections from specific IP addresses of dedicated clients. Then an nftables Firewall is used to only accept VPN communication on Port 51820 for this VM. Those settings were automized by using Ansible scripts. Ansible also made Docker available on this machine.
- The VM has been enriched by installing multiple Docker containers to run a self-hosted Gitea instance and a Traefik reverse proxy. The reverse proxy was necessary (together with DNS settings) to conveniently access the Git server on
git.paulelser.com. On top of that Certbot and Let's Encrypt were used to create TLS certificates that secure the access to the Gitea server. - The fourth step consists of using a Gitea runner and Gitea actions to setup up additional tasks.
- The first task is to create a monitoring possibility on the OCI VM. Therefore the metric collector Prometheus was used in combination with Grafana dashboards.
- However, this is only one side of the setup. In an additonal step, the Gitea action triggered the creation of yet another VM - the Google GCP VM - that is supposed to be facing the public. The GCP VM hosts an Nginx webserver with a very basic message but collects metrics about the state of the server, the type and location of requests to it and information about the VM itself with exporters and then sends them back to Prometheus, which can forward it to a Grafana dashboard that is visible if you recreate that setup for yourself.
Quite some steps necessary for this setup, huh? As mentioned earlier, this project was meant for you to discover a couple of very relevant "cloud" technologies. I am firmly convinced that real-world hands-on experience teaches the most in the shortest amount of time and I am sure that you will learn a lot by trying to replicate this project - as it has been the same for me!
Next Steps
It's no secret that this kind of projects can be enhanced and extended in many different ways. Not everything is absolutely necessary and surely different design choices are very sound aswell. I want to jot down a couple of ideas - honestly mainly to myself.
A Backup Strategy
This is super important and as I already mentioned in my previous article - has had devastating effects on my project already. I was in ~ but though of being in ~/gitea and ran sudo rm -rf .. You can guess that eliminating all the code for Gitea, the runner, the workflows, my monitoring services and the GCP VM creation was shocking at first but taught me a valuable lesson: The effort of creating a backup strategy is time much better spend than mourning deleted data.
I created two scripts in the gitea folder: gitea_backup.sh and gitea_restore.sh that do this job for you when it comes to Gitea data. Of course, this is not foolproof, since you have to run the backup script manually. You could create a cron job that does this for you on a regular basis to not be able to forget to backup.
What about the other things like workflows, code for Terraform and Ansible or even the Grafana dashboard? I think it is easiest to keep this in a repository that you can clone if you need it. However, in this case this must not be your own Gitea repository, since when you accidentally delete it, there is no way of recovering the files. I use a second (private) GitHub repository therefore. You might argue that also Microsoft's GitHub data can get lost - true. If you want to be sure, you can still use the 3-2-1 backup strategy: create at least three copies that you store on two different types of storage media and at least one of them offline. E.g. you might want to create your own NAS for backups.
Security-Audit
Sure, this project was conducted with Security by Design meaning that especially network security best practices were taken into consideration. A careful security audit or penetration test would certainly reveal shortcomings or attack vectors. This must not be disregarded but a lot of attack surface is being covered by the correct architecture. E.g. don't run monitoring services on a publicly accessible machine. In a perfect world you would expect three areas:
- OUTSIDE: The public internet, this is not to be trusted and no critical data must be send there or be accessible from there. The GCP VM would be the example in this project.
- DMZ Zone: This are public services. I don't really have this here and this is a proof that real architectures are not as flat as mine in this project. Theoretically, I would have to have a third VM for the monitoring services alone. However, this is definitely out of the scope in this project. But it makes sense to add this note here. The monitoring servies are in connection between OUTSIDE and INSIDE.
- INSIDE: In this area there are services like Gitea and the reverse proxy. They necessarily need to be reached by services from the DMZ zone but don't have direct connection to OUTSIDE. In my setup I run services intended for the DMZ also on INSIDE.
- ADMIN/TRUSTED: Theoretically you can add a fourth area, too! This would be the control plane or admin space where only commands are issued to the outside world but no communication from the outside reaches this zone. For this project this might be regarded to be my laptop that connects to the jumphost (INSIDE+DMZ) and then also to the GCP VM (OUTSIDE). In a professional setup there would be many more details to it, obviously.
New Technologies
The realm of cloud technologies is far from exhausted with the overview that I gave here. There are many more interesting tools to implement that might add to the learning but also to the complexity of the setup. A couple of things that could be an extension in the future:
- Kubernetes! Of course - why not let Kubernetes orchestrate all the containers instead of Docker compose? Maybe even use a lightweight orchestrator like K3s or K0s. Unfortunately, my Oracle VM only has 1 GB of RAM that already is quite full with the Docker service, Gitea server and a runner that has to perfom actions! There is just no realistic way to add Kubernetes to this machine. However, there might be an antidote: Oracle offers only x86 machines with 1 GB of RAM - ARM machines are staffed with incredible 24 GB of RAM for free! This sounds seductive to me! A next step might involve switching the x86 VM to an ARM-based VM and then a K8s cluster would easily fit on it too.
- Jenkins/Push-based Deployment: Jenkins is used in many CI/CD pipelines in which an action triggers a response. Jenkins is push-based, meaning it needs to be able to establish a connection to its targets. This usually is no problem in server setups. I wanted to go down the route of using Gitea and Actions to push my deployment, but it is not necessary to use Actions and maybe Jenkins might be easier to configure or debug, too. Regardless, Jenkins also needs at least 0.5 - 1 GB of RAM and can't be stuffed on top of the current setup of the limited VM.
- ArgoCD/Pull-based Deployment: ArgoCD has a differnt paradigm in which an agent is running on targets and actively pulls (asks) for new configuration/setup/files. This would be an ArgoCD agent running on the GCP VM and asking for new setup files for the server and container. This certainly doesn't make much sense when it comes to security considerations here. However, another use case can be imagined in which ArgoCD is an integral part of the project learning path.
- ELK-Stack: Yeah, there are alternatives to node-exporter, as I mentioned before I had a couple of attempts. None of them seemed to work too well. A complete ELK stack (ElasticSearch, Logstash, Kibana) is a much more powerful alternative - but also an overkill for the scope of this project. Again, for learning purposes it makes sense to develop a seperate use case that incorporates this technology.
- What else? Well, we restricted ourselves to OCI and GCP - definitely Microsoft Azure and Amazon Webservices AWS can be explored aswell! But to be fair: the UI and the processes to create a compute engine might be different, but it would still be a VM that you can SSH onto and run your commands. Just that you would have to pay real money for it this way 😉
Thanks
Thank you! I hope you had fun - if you have any questions or remarks, never hestitate to contact me 🙏